Hauptteil
1 Grundlagen
Mathematische Grundlagen
Um in die 3D-Programmierung einzusteigen, sind mathematische Grundkenntnisse unverzichtbar. Diese beschränken sich hauptsächlich auf die Vektorrechnung. Damit im Verlaufe dieser Arbeit keine Missverständnisse entstehen, möchte ich deshalb im Folgenden die wichtigsten mathematischen Grundlagen der 3D-Programmierung zusammentragen. Weil die 3D-Programmierung aber eine Anwendung dieser Mathematik ist, werde ich nur die Definitionen und Formeln beschreiben und erklären, wozu man sie benutzt. Auf Beweise werde ich verzichten.
Vektor- und Matrizenrechnung
Länge und Kreuzprodukt
Gegeben sei ein 3D-Vektor  .
.
Seine Länge ist definiert als:

Gegeben seien 2 3D-Vektoren und  und
und  .
.
Das Kreuzprodukt von und ist definiert als:

Der Vektor  steht senkrecht auf
steht senkrecht auf  und
und  . Seine Länge entspricht der Fläche des durch und aufgespannten Parallelogramms, d.h.
. Seine Länge entspricht der Fläche des durch und aufgespannten Parallelogramms, d.h.

Anwendung des Kreuzprodukts
Gegeben sei eine Ebene, die durch drei nicht kolineare Punkte  ,
,  ,
,  definiert ist. Dann bildet der Vektor
definiert ist. Dann bildet der Vektor  den Normalenvektor zur Fläche. Der Normalenvektor wird zur Berechnung von Licht und des Cullings (nur die Dreiecke zeichnen, die in Richtung der Kamera zeigen) benötigt.
den Normalenvektor zur Fläche. Der Normalenvektor wird zur Berechnung von Licht und des Cullings (nur die Dreiecke zeichnen, die in Richtung der Kamera zeigen) benötigt.
Skalarprodukt
Gegeben seien zwei n-dimensionale Vektoren und .
Das Skalarprodukt lautet:

Anwendung des Skalarprodukts
Gegeben seien zwei Vektoren und . Für den Winkel  zwischen und gilt:
zwischen und gilt:

3D-Transformationen
Homogene Koordinaten
Damit alle 3D-Transformationen (siehe Translation) durch Matrizenmultiplikation beschrieben werden können, wird eine vierte Komponente für die Vektoren eingeführt, die w -Komponente. Diese hat folgende Bedeutung:
(Richtungs-) Vektoren haben die w-Komponente 0.
Punkte haben die w-Komponente 1.
Projektiv transformierte Punkte oder Freiformflächen können beliebiges w haben.
Die meisten Transformationen arbeiten mit homogenen Koordinaten, so auch die Hardwareimplementierung. Erst zum Zeichnen der Primitive wird auf 3-dimensionale Koordinaten zurückgerechnet, indem komponentenweise durch die w-Koordinate dividiert wird. Diesen Vorgang nennt man auch perspektivische Division.
Translation
Bei der Translation werden die homogenen Koordinaten hauptsächlich gebraucht. Der um den Translationsvektor verschobene Punkt
lässt sich dann darstellen als
, mit .
Skalierung
Gegeben seien drei Skalierungsfaktoren, und , die ein Objekt in x-, y- und z-Richtung strecken (>1) oder stauchen (<1). Liegt der Fixpunkt im Ursprung so ergibt sich
und die daraus resultierende Transformationsmatrix
.
Rotationen
Rotation um die x-Achse
Die Matrix für eine Rotation um die x-Achse lautet:
Rotation um die y-Achse
Die Matrix für eine Rotation um die y-Achse lautet:
Rotation um die z-Achse
Die Matrix für eine Rotation um die z-Achse lautet:
Die Translation, Skalierung und Rotation sind die grundlegenden Operationen um 3D-Objekte zu transformieren. Ein Vorteil beim Verwenden von Matrizen für die Umformungen ist, dass man die Hintereinanderausführung mehrerer Transformationen durch Matrix-Multiplikation erreicht. Wenn man z.B. eine Translation gefolgt von einer Rotation durchführen möchte, multipliziert man diese beiden Matrizen. Als Ergebnis bekommt man eine Matrix, die beide Transformation enthält. Wenn man einen Punkt mit dieser Matrix multipliziert, werden beide Operationen auf einmal durchgeführt. Hierbei muss man berücksichtigen, dass die Matrix-Multiplikation nicht kommutativ ist, d.h. dass die Reihenfolge in der man die Matrizen miteinander multipliziert ausschlaggebend ist. Bei DirectX kann man sich die Von-Links-Nach-Rechts-Regel merken. Diese sagt, dass die Operationen bei einer Matrix-Multiplikation von links nach rechts angewendet werden. Wenn man beispielsweise zuerst verschieben und dann um die z-Achse rotieren möchte, heißt die resultierende Matrix .
Koordinatensystem und Transformation von Koordinatensystemen
Grundlage aller Objekte im 3D-Raum ist das kartesische Koordinatensystem. Es besteht aus einer x-Achse, y-Achse und z-Achse, die paarweise orthogonal zueinander sind, sich unendlich weit ausdehnen und sich im Ursprung treffen. Ein Vektor ist ein 3-Tupel ((x, y, z)), das die Position auf den drei Achsen relativ zum Ursprung angibt.
Wenn man von einem Punkt spricht meint man nur die angegebene Position. Punkte werden im Folgenden durch Großbuchstaben beschrieben (P). Ein Vektor hat dagegen eine Länge und eine Richtung. Er stellt den Pfeil dar, der auf die angegebene Position zeigt und im Ursprung beginnt. Ein Vektor wird durch Kleinbuchstaben mit einem Pfeil darüber dargestellt (). Die Richtung könnte z.B. die Richtung sein, in die sich ein bestimmtes Objekt bewegt. Die Länge könnte seine Geschwindigkeit darstellen.
Üblicherweise kann man sich beim Koordinatensystem für ein linkshändiges oder ein rechtshändiges Koordinatensystem entscheiden, wobei die positive x-Achse immer nach rechts, die positive y-Achse immer nach oben, und die positive z-Achse beim linkshändigen Koordinatensystem in den Bildschirm hinein und beim rechtshändigen Koordinatensystem aus dem Bildschirm heraus zeigt. Die Bezeichnung links- bzw. rechtshändig kommt daher, dass wenn die Finger der jeweiligen Hand in Richtung positiver x-Achse zeigen, der Daumen die Richtung der z-Achse angibt. Natürlich gibt es auch andere Möglichkeiten, die Achsen zu definieren. Diese werden bei 3D-Modellierungssoftware durchaus benutzt. Zum Beispiel zeigt bei 3D Studio Max die x-Achse nach rechts, die z-Achse nach oben, und die y-Achse in den Bildschirm hinein. Wenn man ein solches Objekt in seine Anwendung laden wollte, müsste man dafür sorgen, dass die Koordinatensysteme übereinstimmen.
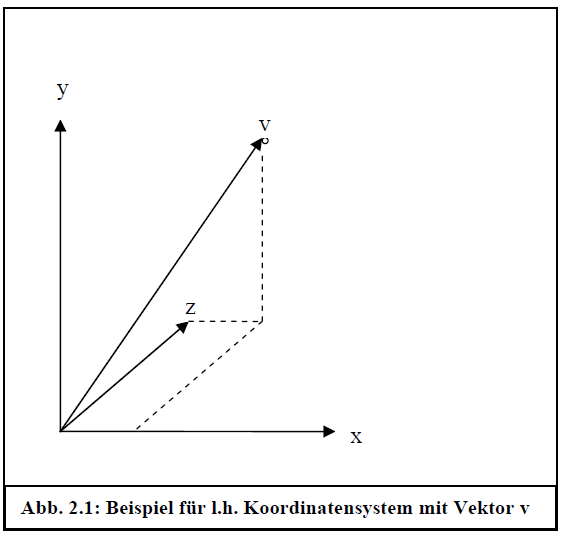
Abb. 2.1: Beispiel für l.h. Koordinatensystem mit Vektor
Diese doch recht einfache mathematische Definition ist Grundlage für ein wichtiges Konzept der 3D-Programmierung: Die Transformation von Koordinatensystemen. Wenn wir ein Koordinatensystem wählen, um die Punkte des zu beschreiben, dann wählen wir damit auch eine Basis, die den Vektorraum aufspannt. Die Basisvektoren sind die Einheitsvektoren in Richtung der Koordinatenachsen. Da die Basisvektoren linear unabhängig sind, kann man jeden Punkt P des Koordinatensystems mithilfe der Gleichung beschreiben, wobei a, b, c Skalare sind und , und die Basisvektoren.
Zwei verschiedene Koordinatensysteme haben zwei verschiedene Basen. Die Transformation von einem Koordinatensystem in ein anderes bedeutet also einen Basiswechsel. Die Basis eines Koordinatensystems kann in Matrixschreibweise mit Zeilenvektoren in homogenen Koordinaten beschrieben werden, wobei die ersten drei Zeilen die Basisvektoren darstellen und die letzte Zeile den Ursprung des Koordinatensystems. Beispielsweise wird ein Koordinatensystem mit kanonischer Basis und Ursprung (0, 0, 0) dargestellt als
Sei B ein weiteres von A verschiedenes Koordinatensystem, welches durch seinen Ursprungspunkt und seine Basisvektoren, , spezifiziert wird, so ergibt sich die Matrix , die den Übergang von Basis B zu Basis A beschreibt als:
Um nun von Koordinatensystem B in Koordinatensystem A zu gelangen, muss jeder Punkt mit der Matrix multipliziert werden. Um einen Punkt von A nach B zu transformieren, muss man ihn mit der Inversen der Matrix multiplizieren:
Managed-DirectX und das .NET-Framework
DirectX ist eine Sammlung von Komponenten, mit denen sich unter Windows lauffähige Multimediaanwendungen entwickeln lassen. Unmanaged-DirectX basiert auf dem Component-Object-Model (COM). Dies sind sprachunabhängige, ortsunabhängige und versionsunabhängige Objekte, die als Dynamic-Link-Lybraries (dlls) eingebunden sind und das Ziel haben, Software auf einfache Weise wieder zu verwenden. COM-Objekte bieten eine Reihe von Funktionen an, die leicht in ein objektorientiertes Design eingebunden werden können. Im Gegensatz dazu benutzt Managed-DirectX das .NET-Framework. Durch die Unabhängigkeit vom aufwändigen COM wird zunächst eine Performance-Steigerung erreicht.
Managed-Code kann in einer von über 20 High-Level-Programmiersprachen wie C#, Visual Basic oder auch C++ geschrieben werden. Dieser wird dann in eine Zwischensprache übersetzt (Intermediate-Language, IL). Alle gemeinsamen Bibliotheken (auch die DirectX-Libraries) liegen auch in IL vor, so dass Sprachunabhängigkeit auf dieser Ebene gewährleistet ist. Ein Laufzeitcompiler übersetzt diese Zwischensprache dann während der Laufzeit in nativen, ausführbaren Code innerhalb einer verwalteten Laufzeitumgebung (Common-Language-Runtime, CLR). So lange also die CLR auf einem Rechner installiert ist, ist Managed-Code auch plattformunabhängig. Die CLR reduziert Programmierfehler, indem sie Typkonsistenz sicherstellt, Array- und Index-Bound-Checks durchführt und Exception-Handling sowie Garbage-Collection anbietet. Dadurch sinkt die Performance allerdings wieder, so dass Managed-Code insgesamt etwas langsamer ist als Unmanaged-Code.
DirectX 9 besteht aus folgenden Komponenten:
DirectX Graphics: API für die gesamte Grafikprogrammierung, inklusive den Direct3D Erweiterungen D3DX zur Erleichterung von Standard-Aufgaben. DirectDraw für 2D-Grafik und Direct3D der früheren Versionen wurden zusammengefasst.
DirectInput: Unterstützung aller gängigen Eingabegeräte.
DirectSound: Unterstützung von Sound-Anwendungen.
Analog zu moderner Computerarchitektur verwendet man bei der 3D-Grafik-Architektur die Optimierungstechniken Pipelining und Parallelisierung. Die Algorithmen, die bei Direct3D verwendet werden sind logisch als 3D–Pipeline organisiert. Diese verläuft analog zur Hardware-Pipeline der Grafikkarte und benutzt deren Algorithmen, wenn dies möglich ist. Man hat üblicherweise mehrere Pixel- und Vertex-Pipelines, die unabhängig voneinander arbeiten können.
Die nächste Generation von DirectX heißt DirectX 10 und verzichtet auf die Abwärtskompatibilität zu älteren DirectX-Versionen. Dadurch können komplett neue, schnellere Bibliotheken geschrieben werden. Ältere Versionen sollen jedoch über eine Softwareschicht zugänglich gemacht werden, was DirectX 9 und ältere Programme verlangsamt. Außerdem werden neue Funktionen wie das Shader-Model 4.0 implementiert.
Die Direct3D-Pipeline
Die Direct3D-Pipeline kann man sich als eine Menge von Algorithmen vorstellen, die auf dreidimensionalen Punkten und Primitiven arbeiten, und deren Ziel es ist, die geometrischen Daten Schritt für Schritt so zu transformieren, dass sie am Ende auf dem Bildschirm oder anderen Render-Targets dargestellt werden. Die Direct3D-Pipeline teilt man in die drei Teile Vertex–Pipeline, Rasterisierung und Pixel–Pipeline auf.
Grafische Attribute
Primitive der DirectX-Pipeline haben ein oder mehrere Attribute, welche die Render-Pipeline für ihre Berechnungen verwendet. Ein Attribut bezieht sich abhängig von Grafik-API und Hardware auf:
Primitive (per-Primitive)
Vertices (per-Vertex)
Pixel (per-Pixel)
Typische Attribute sind:
Position
Farbe
Normale
Materialeigenschaften
Texturkoordinaten
Nebel-Faktor
Grafiksystem-Zustand
Der Zustand des Grafiksystems enthält globale, per-Primitive wirksame Attribute. Er wird von DirectX durch das Device-Objekt zugänglich gemacht. Zu ihm gehören der Render-Zustand (Render-State), der Beleuchtungszustand (Lichtquellen, Material) und der Transformationszustand (World-, View-, und Projection-Matrix). Der Grafiksystem-Zustand kann durch Setzen der Attribute manipuliert werden.
So ergibt sich das Verhalten der Render-Pipeline aus den grafischen Attributen und den Attributen, die den Zustand des Grafiksystems beschreiben.
Vertex-Pipeline
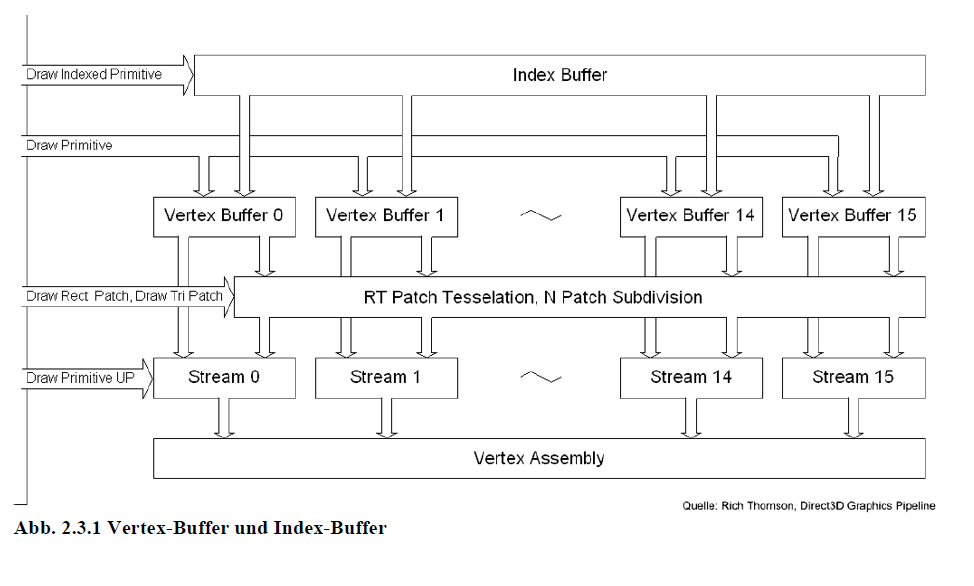
Abb. 2.3.1 Vertex-Buffer und Index-Buffer
Vertex-Buffer
Definiert werden 3D-Objekte durch ihre Eckpunkte (Vertices). Alle untransformierten Eckpunkte einer Szene werden im Vertex-Buffer gespeichert um dann weiterverarbeitet zu werden. Zusammen mit den Vertex-Daten können noch weitere Attribute wie Farbinformationen, Normalen und Texturkoordinaten gespeichert werden. Außerdem kann man ein flexibles Vertex-Format definieren, welches noch andere Attribute wie Binormale und Tangente speichern kann. Diese Daten werden dann vom Vertex-Shader (oder der Fixed-Function-Pipeline) verarbeitet.
Index-Buffer
Der Index-Buffer speichert Referenzen auf die Vertices. Wenn man z.B. ein Quadrat aus Dreiecken zusammensetzt, würde man ohne Index-Buffer zwei Dreiecke an den Vertex-Buffer übergeben, wobei zwei Vertices doppelt vorkommen. Mit Index-Buffer übergibt man nur die vier Eckpunkte des Quadrates und definiert im Index-Buffer, aus welchen Vertices die zwei Dreiecke bestehen.

Abb. 2.3.2 Der Index -Buffer
Auf diese Weise wird der Vertex-Buffer verkleinert und somit die Menge der Daten, die an die Grafikkarte geschickt werden, verringert. Außerdem kann die Grafikkarte die Vertices in einem Vertex-Cache halten und hierauf, statt auf den Vertex-Buffer, zurückgreifen.
Tesselation
Die Tesselation-Einheit konvertiert alle höherwertigen Primitive so, dass sie nur noch aus Eckpunkten bestehen und platziert diese im Vertex-Datenstrom.
Direct3D-Koordinatensysteme (Transformations-Pipeline)
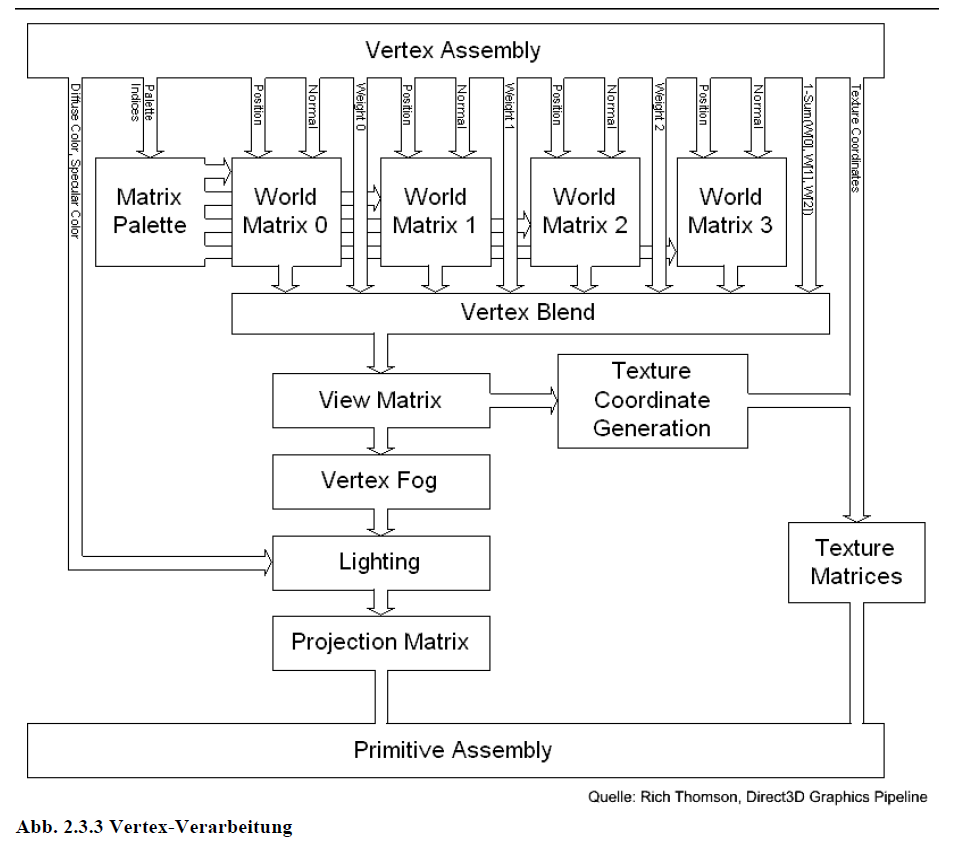
Abb. 2.3.3 Vertex-Verarbeitung
DirectX unterscheidet 4 verschiedene Koordinatensysteme oder Spaces, die durch den Programmierer beeinflusst werden: den Object–Space, den World–Space, den View–Space und den Projection–Space. Man modelliert die Objekte im Object-Space, definiert auf jeder Ebene die Matrix zur Umrechnung ins nächste Koordinatensystem, multipliziert diese miteinander und kann dann mit der resultierenden Matrix einen Punkt direkt vom Object-Space in den Projection-Space transformieren. WaveGen benutzt ein linkshändiges, kartesisches Koordinatensystem. Deshalb wird im weiteren Verlauf der Arbeit nur diese Situation berücksichtigt werden.
Object-Space
Zunächst wird jedes 3D-Objekt in seinem lokalen Object-Space definiert (Modeling). Hier ist der Ursprung der Rotationspunkt des Objektes. Dieser Space gehört eigentlich noch nicht zur Transformationspipeline. Er stellt vielmehr die Menge der Eckpunkte im Vertex-Buffer bzw. Index-Buffer dar.
World-Space
Da alle Objekte einer 3D-Szene in einer gemeinsamen Welt existieren, müssen ihre lokalen Koordinaten so umgeformt werden, dass sie einen gemeinsamen Ursprung haben. Dazu definiert man für jedes Objekt eine so genannte Weltmatrix, die das Objekt in Weltkoordinaten transformiert. Die Menge der Objekte, die in Weltkoordinaten beschrieben sind, nennt man Szene.
Wenn man nun annimmt, dass die Richtungsvektoren =(1, 0, 0), =(0, 1, 0) und =(0, 0, 1) die Basis des lokalen Koordinatensystems darstellen, und p der Vektor sei, der die Position des Objektkoordinatensystems im World-Space angibt, so ergibt sich die Situation aus dem Kapitel zur Transformation von Koordinatensystemen (2.1.3) und man kann mit der Weltmatrix
das lokale Koordinatensystem in den World-Space transformieren.
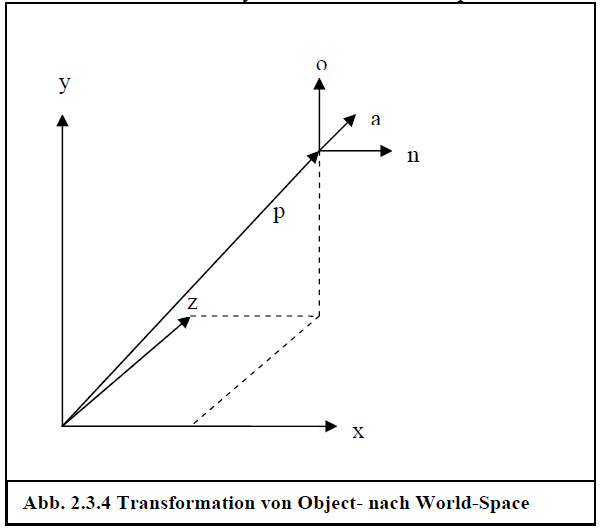
Abb. 2.3.4 Transformation von Object- nach World-Space
View-Space
Der View-Space definiert, aus welchem Blickwinkel die 3D-Bilder auf dem Bildschirm zu sehen sind. Dies kann man sich so vorstellen als würde man aus einer Kamera, die sich an einer bestimmten Stelle im World-Space befindet, in eine gewisse Richtung schauen. Das, was die Kamera dann sieht, ist der View-Space oder Camera-Space. Hier ergibt sich der umgekehrte Fall der Transformation vom Object-Space in den World-Space: Man kennt die Basis und den Ursprung des Ziel-Koordinatensystems (View-Space), welches sich im Quell-Koordinatensystem (World-Space) befindet. Seien die Vektoren , , und wieder die entsprechenden Achsen sowie der Ursprung des View-Space, so ergibt sich als Transformationsmatrix die Inverse zur ursprünglichen Matrix:
Anmerkung:
Diese Formel zur Berechnung der Inversen ist nicht allgemein gültig. Sie funktioniert nur, wenn die Matrix eine Komposition von Translationen, Rotationen und Reflexionen ist, was aber bei der 3D-Programmierung zutrifft. Abb. 2.3.5 verdeutlicht die Transformation in den View-Space noch einmal.
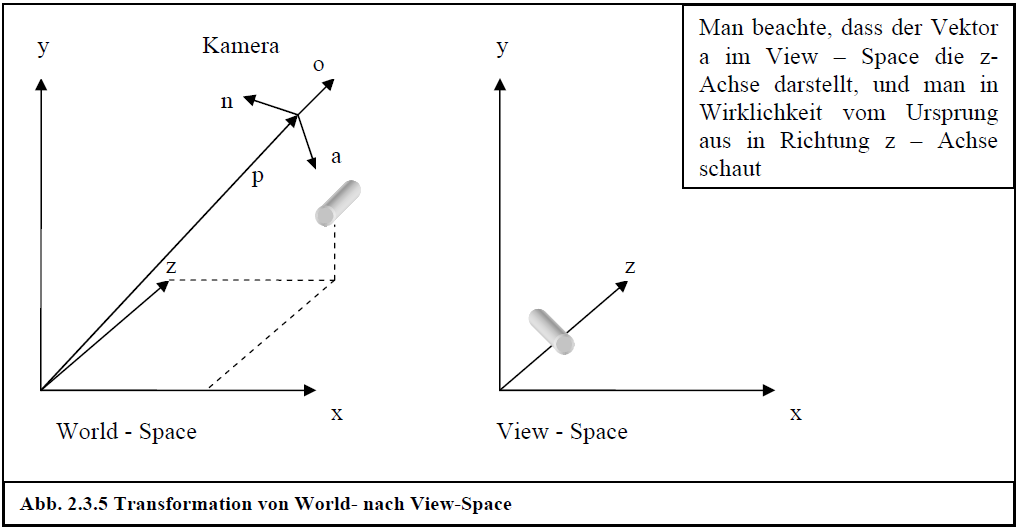
Abb. 2.3.5 Transformation von World- nach View-Space
Bei DirectX gibt man nun aber nicht direkt die Basis des View-Spaces an, sondern die Kameraposition (Eye-Point), die Kamerarichtung (Look-At-Point) und den Up-Vector (normalerweise y-Achse). Die lokalen Achsen der Kamera werden dann folgendermaßen berechnet:
a = normalize(cameraLookAtPoint – cameraEyePoint)
n = normalize(cross(cameraUpVector, a))
o = cross(a, n)
/*
Hierbei berechnet normalize() den Einheitsvektor und cross() das Kreuzprodukt.
*/
Projection-Space
Im letzten Schritt der so genannten Transformations-Pipeline berechnet man nun vorläufige 2D-Koordinaten und Tiefeninformationen der Szene im so genannten Projection-Space. Weil es viele Möglichkeiten der Projektion auf 2D-Koordinaten gibt und die Herleitungen sehr komplex sind, werde ich hier nur kurz auf die gängige Projektion (perspektivische Projektion) eingehen, die auch bei WaveGen benutzt wird. Die perspektivische Projektion bewirkt unter anderem, dass nahe Objekte größer und weiter entfernte Objekte kleiner dargestellt werden.
Grundlage der Projektion ist ein so genanntes Viewing-Frustum. Dieses kann man sich als Pyramide vorstellen, die relativ zur Kamera verläuft und durch eine Front-Clipping-Plane (vordere Schnitt-Ebene) und eine Back-Clipping-Plane (hintere Schnitt-Ebene) begrenzt ist. Der Pyramidenstumpf, der dadurch entsteht ist das Viewing-Frustum. Alles, was sich innerhalb dessen befindet, ist nachher auf dem Bildschirm sichtbar.
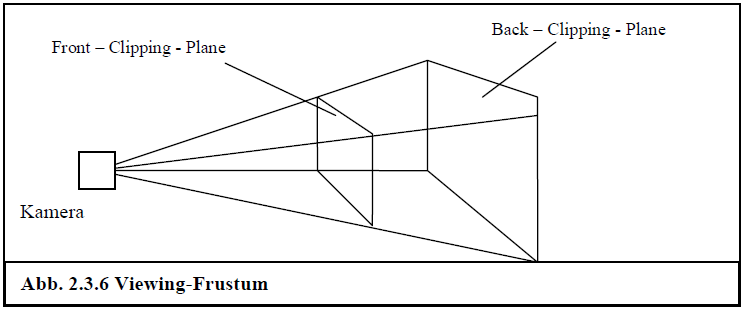
Abb. 2.3.6 Viewing-Frustum
Definiert wird dieses Viewing-Frustum durch einen horizontalen Field-Of-View (fov), den man sich als Brennweite der Kamera vorstellen kann und die Position der Clipping-Planes in z-Koordinaten ( und ).
Erstes Ziel dieser Projektion ist es, die x- und y-Koordinaten so zu skalieren, dass sie das Verhältnis von Viewport (Ausgabefenster)-Breite zu Viewport-Höhe (aspect ratio) berücksichtigen. Wird z.B. immer ein quadratischer Viewport (aspect ratio: 1) vorausgesetzt, sieht das Ergebnis auf einem rechteckigen Viewport vertikal gedrückt aus.
Des Weiteren sollen sich die x-, und y-Koordinaten im Bereich -1.0 bis 1.0 befinden. Die z-Koordinaten sollen ihre relative Tiefe beibehalten, da sie später dem Z-Buffer übergeben werden. Sie sollen sich im Bereich 0.0 bis 1.0 befinden. Dies ist notwendig, weil der Z-Buffer nur solche Werte verarbeitet. Der Pyramidenstumpf wird also in einen Quader projiziert.
Außerdem sollen weit entfernte Objekte kleiner und nahe Objekte größer aussehen, was dadurch erreicht werden kann, dass man die x- und y-Koordinaten durch z teilt.
Dadurch ergeben sich folgende Werte in Abhängigkeit der Höhe und Breite des Viewports und des Field-Of-View:
Damit lautet die Projektionsmatrix:
Wenn man nun einen Punkt transformiert, sieht man, dass die geforderten Merkmale der Projektion erfüllt sind, nachdem die perspektivische Division (Division durch w-Koordinate) durchgeführt ist:
Nach perspektivischer Division:
Man erkennt:
Die sichtbaren x- und y-Werte werden durch die Multiplikation mit w und h nach
[-1.0; 1.0] skaliert und durch die Division durch z perspektivisch verkürzt. Die sichtbaren z-Werte sind zwischen 0.0 und 1.0 und behalten ihre relative Tiefe.
Jetzt befindet man sich im so genannten Projection- oder Clipping-Space, welcher ein Quader mit Tiefe 0.0 bis 1.0 und Breite bzw. Höhe von -1.0 bis 1.0 darstellt. Zu beachten ist, dass die perspektivische Division erst zu einem späteren Zeitpunkt geschieht.
Wenn man nun einen Punkt vom Object-Space in den Projection-Space transformieren möchte, ergibt sich folgenden Formel:
Wie man in Abb. 2.3.3 sieht, werden diese Transformationen jedoch nicht sofort hintereinander ausgeführt. Im View-Space wird noch der Vertex-Fog und das Vertex-Lighting berechnet. Auch die Generierung von Texturkoordinaten geschieht hier nach der Transformation in den View-Space. Möchte man die Texturkoordinaten z.B. im World-Space haben, wird eine Transformation der Texturkoordinaten (mit der inversen View-Matrix) notwendig. Dies wird bei WaveGen z.B. für das Cube-Mapping gebraucht. Da die Beleuchtung auch hier berechnet wird nennt man diesen Abschnitt auch Transform-And-Lighting-Pipeline. Das Lighting und das Texturing werden in Kapitel 2.4 genauer beschrieben.
Verarbeitung der Primitive
Vom Projection-Space aus werden die Eckpunkte in Primitive umgewandelt, die durch einen Befehl gezeichnet werden können (Primitive-Assembly). Bei der aktuellen Grafikhardware sind dies Dreiecke, Linien oder Punkte. Dann werden die Primitive noch einigen Verarbeitungsschritten unterzogen, bevor sie rasterisiert und in Pixelform weiterverarbeitet werden.
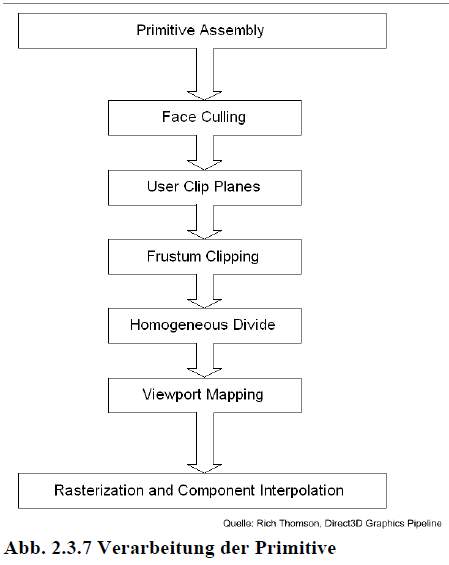
Abb. 2.3.7 Verarbeitung der Primitive
Face-Culling
Normalerweise werden beide Seiten der Dreiecke gerendert. Durch die Definition einer Betrachterrichtung im View-Koordinatensystem, kann man durch den Drehsinn des Dreiecks berechnen, welches die Vorder- und Rückseite ist. Im Render-Zustand definiert man dann anhand des Drehsinns (im oder gegen den Uhrzeigersinn), welche Seite des Dreiecks nicht gerendert werden soll.
User-Clip-Planes
Bei manchen Grafikkarten kann man eigene Clip-Planes definieren, gegen die der Clipping-Algorithmus das Clipping zusätzlich zu den 6 Ebenen des Sichtvolumens durchführt.
Clipping
Das Clipping hat die Aufgabe, Teile von Primitiven (Eckpunkte und Teile von Kanten) zu entfernen, die über das Sichtvolumen hinausragen. Im Clipping-Koordinatensystem kann das Clipping in sechs Schritten gegen die sechs Ebenen durchgeführt werden.
Perspektivische Division (Homogenous-Divide)
Die perspektivische Division überführt die homogenen Koordinaten in 3D-Koordinaten, indem sie jede Komponente durch die w-Koordinate teilt.
Viewport-Mapping
Zum Schluss transformiert DirectX diese Koordinaten noch in die Viewport- oder Screen-Koordinaten, wodurch der Transformationsprozess abgeschlossen ist und die weiteren Aufgaben an den Rasterizer übergeben werden. Die z-Koordinate wird als Tiefeninformation für den Z-Buffer gespeichert.
Rasterisierung
Bei der Rasterisierung wird berechnet, welche Pixel von der projizierten Fläche der Primitive überdeckt werden. Da dies durch die feste Pixelgröße nicht perfekt möglich ist, entsteht das so genannte Aliasing (Treppcheneffekt). Außerdem werden alle Eckpunktattribute entsprechend der affinen Koordinaten der Pixel interpoliert. Zunächst werden inkrementell alle Schnittpunkte der (nicht horizontalen) Primitivkanten mit den Pixelzeilen bestimmt und die Attribute an diesen Punkten interpoliert (Primitive-Setup). Dann werden für jede horizontale Spanne, in der ein Primitiv eine Pixelzeile überdeckt, inkrementell die Attribute an den Pixelpositionen interpoliert.
Pixel-Pipeline
Die Pixel, die durch die Rasterisierung berechnet wurden, werden nun in zwei Phasen bearbeitet. Zunächst wird die Pixelschattierung oder Texturverarbeitung vorgenommen, dann die Bildschirmpufferoperationen.
Texturverarbeitung
Bei der Texturverarbeitung werden die Pixelattribute in mehreren Stufen mit den Texturwerten verrechnet (Multi-Texturing). Sie gliedert sich auf in Texturabtastung und Texturanwendung. Das Ergebnis der letzten Texturstufe ist die Farbe und Opazität des Pixels. Oft ist auch das so genannte Bump-Mapping in der Hardware implementiert. Die Position der Pixel (in Bildschirmkoordinaten) und der Nebel-Faktor sowie der Tiefenwert bleiben unverändert.
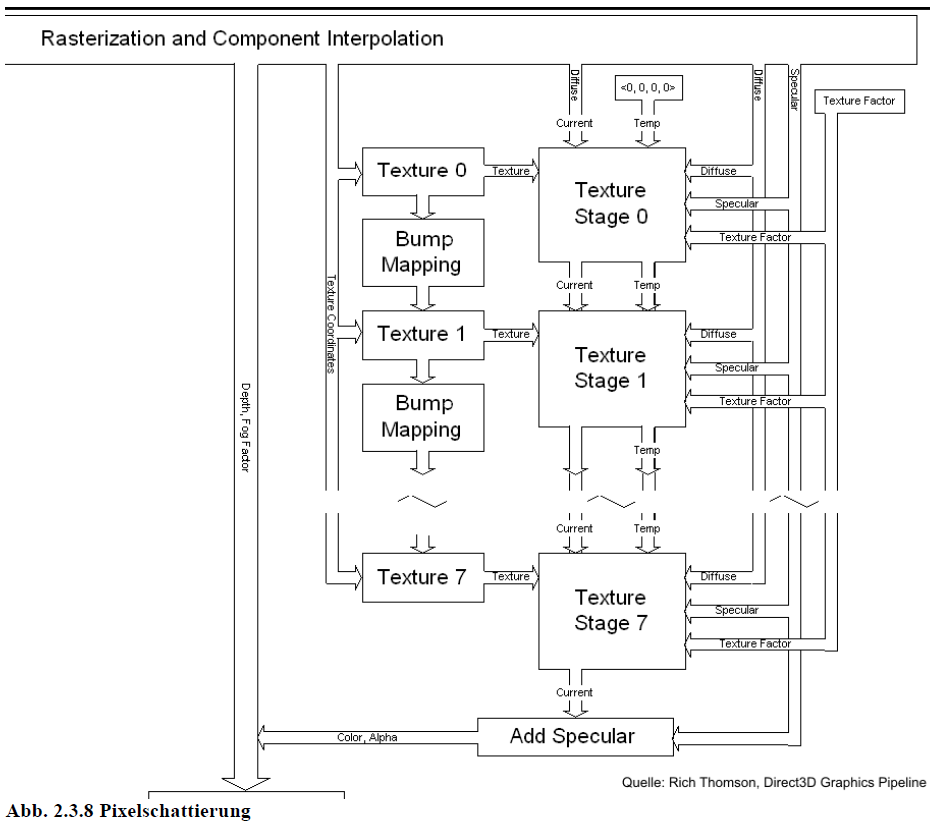
Abb. 2.3.8 Pixelschattierung
Texture-Sampling (Texturabtastung)
Bevor es zur Texturanwendung (Texture-Stage) kommt, stellt ein Texture-Sampler die interpolierten Texturkoordinaten der Texturstufe zur Adressierung und Filterung einer Textur zur Verfügung.
Texturanwendung
In jeder Texturstufe wird der Abtastwert, der beim Texture-Sampling ermittelt wurde mit einigen Attributen der Texturstufe verknüpft. Die Texturverarbeitung wird in Kapitel 2.4 genauer erläutert.
Bildschirmpufferoperationen
Mit den Bildschirmpufferoperationen werden die einzelnen Pixel noch einigen Tests unterzogen. Pixel, die alle Tests erfüllen werden in den Pixel-Buffer, den Z-Buffer oder andere Puffer geschrieben. Die Tests können im Render-Zustand an- und abgeschaltet bzw. parametrisiert werden.
Abb. 2.3.9 Bildschirmpufferoperationen
Nebel-Überblendung (Fog-Blend)
Der interpolierte Nebel-Wert wird mit der Pixelfarbe überlagert.
Alpha-Test
Der Alpha-Wert des Pixels wird mit einem festen Bezugswert verglichen. Zum Vergleich kann man einen Vergleichsoperator (<, >, =, …) wählen.
Tiefentest (Depth-Test)
Der Tiefentest vergleicht den aktuellen Tiefenwert des Pixels mit der Tiefe im Z-Buffer. Der Vergleichsoperator ist standardmäßig <. Dies bedeutet, dass der Farbwert des aktuellen Pixels mit dem des Pixels im Z-Buffer ersetzt wird, wenn er kleiner, also näher am Betrachter ist.
Stencil-Test
Es gibt einen so genannten Stencil-Buffer, der einen zu vergleichenden, pixelabhängigen Wert liefert. Ein Referenzwert und der Stencil-Wert werden jeweils mit einer Bitmaske und einem bitweisen UND verknüpft wurden. Dieser Wert wird mit dem Ergebnis des Z-Buffers verglichen und kann drei Ergebnisse liefern:
sowohl Tiefen- als auch Stencil-Test erfolgreich
Stencil-Test erfolgreich und Tiefentest erfolglos
Stencil-Test erfolglos
Abhängig vom Ergebnis kann dann eine Operation definiert werden, die den Stencil-Buffer-Wert erhöht, erniedrigt, null setzt oder Ähnliches. Nur im ersten Fall sind beide Tests bestanden und das Pixel wird weiterverarbeitet. Der Stencil-Test ist ein Hack, der für Maskierungen und Zählvorgänge benutzt wird, z.B. zur Schattenberechnung.
Alpha-Überblendung (Alpha-Blend)
Das zu rendernde Quellpixel (Source) wird mit dem bisherigen Zielpixel (Destination) überblendet. Standardmäßig wird hier die Opazität des Quellpixels (Alpha) mit der des Zielpixels (1 – Alpha) überblendet. Die so erzeugte Mischfarbe stellt Objekte transparent dar.
Kanalmaske (Channel-Mask)
Hier wird ausgewählt, welche der Attribute Farbe, Opazität, Tiefenwert und Stencil-Wert in die einzelnen Puffer geschrieben werden. Diese Puffer sind ein Pixel-Buffer für Farbe ein Pixel-Buffer für Opazität, der Z-Buffer und der Stencil-Buffer.
Render-Target
Die Zielpuffer, die das Render-Target darstellen, werden beschrieben.
Vertex- und Pixel-Shader
Sowohl auf der Vertex- als auch auf der Pixel-Ebene muss man sich nicht auf die fest vorgegebenen Algorithmen beschränken. Seit DirectX 8 gibt es die Möglichkeit, diese Funktionen selbst zu programmieren. Die Vertex- und Pixel-Shader sind Speicherbereiche auf der Grafikkarte, in die man eigene Assembler-Programme laden kann. Diese ersetzen dann die jeweiligen Fixed-Function-Pipelines und werden von der GPU ausgeführt.
Der Vertex-Shader ersetzt die Transform-And-Lighting-Pipeline. Er empfängt einen Datenstrom von Vertices mit Eckpunktattributen wie Normale und Texturkoordinaten. Das Programm wird dann auf jeden einzelnen Eckpunkt angewendet. Hier sollte man daran denken, dass die Vertices wenigstens in den Projection-Space transformiert werden müssen, da die Transformation über die Fixed-Function-Pipeline ausgeschaltet ist.
Der Pixel-Shader ersetzt die Pixelschattierung der Pixel-Pipeline. Er übernimmt Daten des Vertex-Shaders sowie Texture-Maps aus der Anwendung, verarbeitet diese und gibt einen Farbwert für das jeweilige Pixel zurück.
Da der Vertex- und Pixel-Shader Maschinenprogramme beinhalten, sind sie relativ schwierig zu programmieren. Deshalb gibt es diverse High-Level-Sprachen, die in die Maschinensprache übersetzt werden. WaveGen benutzt die HLSL (High-Level-Shader-Language), die kompatibel zu der von NVIDIA entwickelten Cg (C for graphics)-Sprache ist. Ein einfaches Shader-Programm wird in Kapitel 5.10 implementiert. Eine Dokumentation von Cg findet man unter [11].
Beleuchtung (Lighting) und Texturierung (Texturing)
Wegen der Komplexität des Themas wird in diesem Kapitel die Texturierung und Ausleuchtung einer Oberfläche näher erläutert. Das Wort Lighting wird meistens für den Prozess der Berechnung der Lichtmenge, die auf eine Oberfläche fällt benutzt. Das Wort Shading beschreibt die Methoden, die angewandt werden, um die Farbe und Intensität des Lichtes für jedes Pixel der Oberfläche zu berechnen, das in Richtung Beobachter reflektiert wird. Man kann auch sagen, dass das Lighting den Beleuchtungswert an den Vertices berechnet (Per-Vertex-Lighting) und das Shading diese Werte dann über die Dreiecke interpoliert. Die Farbe der Pixel hängt von den Lichtquellen der Szene und den Reflexionseigenschaften der Oberfläche ab. Da die Beziehung zwischen Licht und Oberfläche ein sehr komplexer physikalischer Prozess ist, kann man mit heutiger Hardware die Realität nur mit geeigneten Lichtmodellen approximieren.
Das RGB-Farbsystem
Die erste Vereinfachung beim Lichtmodell besteht in der Berechnung der Farbe des Lichtes. Man betrachtet nicht jede Wellenlänge, sondern nur diejenigen für rotes, grünes und blaues Licht und kombiniert diese dann zu einer Gesamtfarbe, indem man Anteile der drei Farben angibt. Nach diesem Schema stellen auch analoge Computermonitore ihre Farben dar.
Die RGB-Farbe besteht also aus einem 3-Tupel, das den Anteil von Rot, Grün und Blau im Bereich 0.0 bis 1.0 angibt. So kann man sowohl die spektrale Komposition (Farbe) als auch die Intensität des Lichtes beschreiben. Außerdem kann man noch eine vierte Komponente (Alpha-Wert) hinzufügen, der die Opazität (Lichtundurchlässigkeit) eines Pixels beschreibt. Dieses Modell nennt man dann RGBA.
RGB-Farben werden komponentenweise addiert und multipliziert. Die Farbe eines Pixels, das zu einem bestimmten Primitiv gehört, ergibt sich nun aus mehreren Quellen. Normalerweise berechnet sie sich aus der Farbe, die in einer gefilterten Texture-Map über die interpolierten Texturkoordinaten ermittelt wurde und einer Reflexionsfarbe, die über die Eckpunkte des Dreiecks nach einem bestimmten Beleuchtungsmodell interpoliert wurde. Wenn diese beiden Farben multipliziert werden, spricht man auch von einer Modulation.
Eckpunktschattierung (Per-Vertex-Lighting)
Die grundlegenden Lichtreflexionen werden an den Eckpunkten berechnet und dann zur weiteren Verarbeitung in den Vertex-Attributen gespeichert.
Lichtquellen
Zunächst definiert man die Lichtquellen, die für die gesamte Szene gelten und deren Position deshalb in Weltkoordinaten angegeben wird. Die Lichtquellen senden eine bestimmte Lichtintensität aus, die dann evtl. abgeschwächt auf die Oberfläche trifft. Anhand dieser Intensität wird mit den verschiedenen Lichtarten die Beleuchtung berechnet.
Gerichtetes Licht (Directional-Light)
Dies ist die einfachste Lichtquelle. Sie besteht aus zueinander parallelen Lichtstrahlen, scheint auf die gesamte Szene und wird durch einen Vektor festgelegt der die Richtung der (unendlich weit entfernten) Lichtquelle angibt. Gerichtetes Licht wird nicht abgeschwächt und der Einfallsvektor ist immer gleich, so dass der diffuse Reflexionsfaktor immer gleich ist. Die führt dazu, dass gerichtetes Licht sehr ressourcenschonend ist.
Punktlicht (Point-Light)
Point-Lights sind unendlich kleine Punkte, von denen sich das Licht gleichmäßig in alle Richtungen ausbreitet. Physikalisch korrekt nimmt die Lichtintensität mit dem Quadrat der Entfernung ab. Praktisch verwendet man aber oft keine oder eine lineare Abschwächung, weil das menschliche Auge sich schlecht an eine schnelle Abschwächung von Licht bei Computergrafik gewöhnt. Außerdem muss für jede Vertex-Position die Richtung der Lichtstrahlen berechnet und normiert werden:
Spotlight
Spotlights scheinen kegelförmig in eine bestimmte Richtung und sind sehr teuer. Sie können jedoch sehr schöne Effekte erzielen und haben deshalb durchaus ihre Berechtigung, solange die Ressourcen ausreichen. Oft kann man jedoch einen ähnlichen Effekt durch die Texturierung mit einer Light-Map erreichen.
Beleuchtungsmodelle
Im Gegensatz zu einem globalen Beleuchtungsmodell, das auch sekundäre Lichtquellen berücksichtigt, beziehen sich die Reflexionseigenschaften der Objekte bei DirectX nur auf die oben definierten (primären) Lichtquellen. Sie geben keine Reflexionen an andere Objekte weiter. Daher spricht man von einem lokalen Beleuchtungsmodell. Das lokale Beleuchtungsmodell von DirectX unterscheidet vier Formen von Licht, die von einer Oberfläche reflektiert werden können. Aus den Reflexionseigenschaften (reflektierende Farbe) der Oberfläche und der Farbe der Lichtquellen berechnet sich dann die Beleuchtungsfarbe an den Vertices.
Ambientes Licht (Umgebungslicht)
Das ambiente Licht ist die Grundbeleuchtung einer Szene. Es wird gleichermaßen zu allen Punkten auf allen Oberflächen ausgesendet. Dieses Licht ist dazu da, das Fehlen von sekundären Lichtquellen auszugleichen, die es beim bei globalen Beleuchtungsmodellen wie Raytracing gibt. Da die Objekte beim DirectX-Lichtmodell nur das Licht von den primären Lichtquellen reflektieren, gibt es das ambiente Licht um die weiteren Reflexionen auszugleichen. Es ist also im Prinzip ein Hack, der viel Zeit spart.
Diffuses Licht
Diffuses Licht wird beim Treffen auf eine Oberfläche in alle Richtungen reflektiert. Oberflächen, die ausschließlich diffuses Licht reflektieren, scheinen immer gleich beleuchtet zu sein, egal aus welcher Richtung die Kamera auf sie schaut.
Spekulares Licht (Spiegelnde Reflexion)
Spekulares Licht wird nur in eine spezielle Richtung von der Oberfläche reflektiert. Dies erzeugt einen leuchtenden Punkt auf der Oberfläche. Die Position dieses Punktes hängt von der Position der Lichtquelle und der Position des Betrachters ab.
Emissives (aussendendes) Licht
Emissives Licht wird von einem Objekt ausgesendet. Dieses Licht beeinflusst allerdings nicht die Erscheinung anderer Objekte der Szene, da es keine eigene Lichtquelle darstellt. Es beeinflusst lediglich das Aussehen der Oberfläche von der es ausgesendet wird.
Phong/Blinn Beleuchtungsmodell
Durch die Definition der Lichtquellen und der Lichtarten kann man nun die gesamte Beleuchtung berechnen. Das Modell nach Phong wurde 1975 entwickelt und 1977 von Bling vereinfacht. Es ist ein empirisches Modell (nur bedingt physikalisch begründet) und nahezu in jeder Grafikhardware implementiert.
Das reflektierte Licht setzt sich aus drei additiven Anteilen zusammen: einem Diffusen, einem Spekularen und einem Ambienten. Natürlich muss die Berechnung für jede Lichtquelle der Szene ausgeführt werden. Die Intensitäten und Lichtrichtungen ergeben sich aus der Art der Lichtquelle. Die Formel nach Phong/Blinn zur Beleuchtung von Eckpunkten lautet also:
, mit
: diffuse Materialfarbe
: spekulare Materialfarbe
: ambiente Materialfarbe
: diffuse Lichtintensität je Lichtquelle I
: spekulare Lichtintensität je Lichtquelle I
: ambiente Lichtintensität je Lichtquelle I
Die Intensitäten berechnen sich folgendermaßen:
Diffuse Reflexion (Lamberts Gesetz)
Der diffuse Anteil bildet die Reflexion an einer ideal matten Oberfläche gemäß dem Gesetz von Lambert nach:
Die flächenbezogene, einfallende Lichtmenge ist proportional zum Cosinus des Winkels zwischen Oberflächennormale und Vektor zur Lichtquelle aber nicht negativ
Das Licht wird in alle Richtungen gleichmäßig reflektiert
Dies führt zu: , mit
: einfallende Intensität
: normierter Vektor zur Lichtquelle
: normierte Normale zur Oberfläche
: diffus reflektierte Intensität
Spekulare Reflexion
Ideal spiegelnde Objekte reflektieren einfallendes Licht derart, dass Einfalls- und Ausfallswinkel des Lichtes gleich sind.
Dem Phong-Modell liegt wenigstens eine der folgenden Annahmen zugrunde:
Reale spiegelnde Oberflächen erzeugen ein um den Ausfallswinkel
symmetrisches Glanzlicht, mit einem materialabhängigen Intensitäts-Abfall
Reale Lichtquellen sind nicht punktförmig und können durch eine nicht-ideale
Spiegelung ersetzt werden
Das Phong-Modell verwendet eine empirische, einfach zu berechnende Funktion für
den Intensitäts-Abfall:
Dabei ist:
: normierter Spiegelvektor, d.h. an der Normale gespiegelter normierter Vektor zur Lichtquelle
: normierter Vektor zum Betrachter
: Phong-Exponent (shininess); gibt die Perfektion der Spiegelung an
Da R sehr schwierig zu berechnen ist, gibt es einen billigeren Ersatz (Blinn 1977):
, mit
H: normierte Winkelhalbierende zwischen L und V, also
Wie bei der diffusen Reflexion müssen die Werte noch auf nichtnegative Werte begrenzt werden.
Ambiente Reflexion
Die Umgebungslichtintensität ist für eine Szene konstant, weil sie unabhängig von der Geometrie reflektiert wird.
Bei DirectX wird zusätzlich zu der Formel von oben noch ein Term für das emissive Licht addiert.
Materialparameter
Die Materialparameter (Reflexionskoeffizienten) beschreiben für jedes Objekt welche Lichtfarben es von welchem Licht reflektiert (, , ). Da diese für ein gesamtes Objekt gleich sind, werden sie im Render-Zustand definiert. Sie bewirken eine subtraktive Farbmischung mit den gemäß der Geometrie reflektierten Lichtintensitäten. Sie lassen also nur die Farbanteile des reflektierten Lichtes durch, die zur Materialfarbe gehören.
Nun hat man durch das Beleuchtungsmodell die Lichtwerte an den Eckpunkten berechnet. Diese müssen in der Pixel-Pipeline noch über das Dreieck interpoliert werden, so dass jedes Pixel in Abhängigkeit von der Eckpunktschattierung eine möglichst realistische Farbe hat. Die Pixel-Schattierung nennt man auch Shading.
Die Unterscheidung zwischen Eckpunktschattierung und Pixel-Schattierung schlägt sich auch in der (etwas verwirrenden) Namensgebung der programmierbaren Pipelines (Vertex- und Pixel-Shader) nieder, die ja nicht ausschließlich für die Schattierung zuständig sein müssen. Wenn man allerdings den Vertex-Shader bzw. den Pixel-Shader benutzt, muss man die Beleuchtungsberechnungen selbst programmieren.
In der Fixed-Function-Pixel-Pipeline unterstützt DirectX Flat- und Gouraud-Shading. Phong-Shading wird in einer vereinfachten Version unterstützt und nennt sich Specular-Lighting. Dieses muss im Render-State angeschaltet werden.
Pixel-Schattierung (Shading)
Der Wert der bei der Interpolation entlang der Primitivkanten entsteht, speichert jedes Pixel als Pixel-Attribut. Derzeit existieren drei Verfahren, um diesen Wert zu berechnen.
Flat-Shading
Hierbei ist die Interpolation abgeschaltet. Jedes Primitiv bekommt die Farbe seines ersten Eckpunktes. Bei dieser Shading-Variante erkennt man die einzelnen Primitive einer gewölbten Oberfläche. Dies ist die schnellste, aber auch unrealistischste Form von Shading.
Gouraud-Shading
Gouraud-Shading ist das Standardverfahren der Grafikhardware. Die Pixelfarben werden hier zwischen den Eckpunktfarben linear interpoliert, wodurch ein kontinuierlicher Farbverlauf entsteht.
Phong- (Pixel-) Shading
Hierbei wird für jedes Pixel die interpolierte Normale verwendet, um eine vollständige Berechnung des Phong-Beleuchtungsmodells durchzuführen. So können Glanzlichter auch auf der Fläche eines Primitivs entstehen. Das Verfahren ist sehr aufwendig und wird daher normalerweise nicht implementiert.
Texturierung
Das Shading führt zu kontinuierlich gefärbten Flächen. Um eine realistische und abwechslungsreiche Oberflächenstruktur und -farbe zu erreichen, verwendet man Texturen. Dies sind ein- oder mehrdimensionale Felder von Elementen, die Texel genannt werden. Texel sind per-Pixel-Attribute, die in mehreren Stufen auf die Primitive angewendet werden. Damit ein Primitiv z.B. wie eine Mauer aussieht, legt man das Bild einer Mauer als Textur über das Primitiv.
Um unabhängig von der Auflösung der Textur zu sein, wird sie in ein Texturkoordinatensystem eingebettet, welches in jeder Dimension von 0.0 bis 1.0 reicht. Texturkoordinaten sind per-Vertex-Attribute, die ebenfalls über die projizierte Fläche des Primitivs interpoliert werden. Wenn Texturkoordinaten explizit vom Programmierer angegeben werden, muss dieser darauf achten, dass sie sich innerhalb des Texturkoordinatensystems befinden. Koordinaten, die außerhalb dessen sind, können auf verschiedene Weise behandelt werden (Wrap, Mirror, Clamp, Border-Color). Außerdem gibt es noch mehrere Möglichkeiten Texturkoordinaten generieren zu lassen.
Da eine Textur das Primitiv betrachterunabhängig überspannen soll, müssen die Koordinaten in Clipkoordinaten interpoliert werden. Weil aber die Rasterisierung eines Primitivs in Bildkoordinaten geschieht, ist eine Rücktransformation aus dem Screen-Space in den Clipping-Space notwendig. Das geschieht durch die Division durch das ebenfalls in Bildschirmkoordinaten interpolierte „reziproke homogene w“, ().
Heutzutage beherrscht jede Hardware perspektivisch korrektes Texture-Mapping. Der Pixel-Schattierung liegen diese (perspektivisch korrekten) Texturkoordinaten bereits vor.
Mit den Texturkoordinaten können nun die Pixel der Primitive mit den entsprechenden Farben der Texture-Map gefüllt werden, und mit anderen Attributen wie etwa der diffusen Reflexionsfarbe überblendet werden. Insgesamt können bei DirectX acht Texturen überblendet werden, die in Texturstufen (Texture-Stages) organisiert sind und in aktueller Hardware sehr flexibel konfigurierbar sind. Eine Texturstufe sieht folgendermaßen aus:
Abb. 2.4.1 Texturstufe
Jede Texturstufe bekommt folgende Eingangsattribute:
Texturfarbe
aktuelle Farbe aus der Pixel-Schattierung (z.B. Gouraud-Schattierung)
diffuse Materialfarbe (Interpoliertes Vertex-Attribut oder Konstante aus dem Render-Zustand)
spiegelnde Materialfarbe (Konstante aus dem Render-Zustand)
Texturfaktor (Konstante aus dem Texur-Zustand)
temporäres Register
Aus diesen Attributen können dann drei ausgewählt werden die durch eine Operation verknüpft werden. Operationen können sein:
Selektion eines Attributes
komponentenweise Addition, Subtraktion, Multiplikation (Modulate)
In den Texturstufen wird auch das Alpha-Blending für Texturen angewandt. Dabei definiert man, welche Pixel transparent dargestellt werden sollen und auf welche Weise dies geschieht.
Man benötigt allerdings ein Texturformat, das einen Alpha-Kanal besitzt.
Die Texturstufen erlauben es, Beleuchtungsmodelle zu berechnen, die fast alle per-Pixel-Attribute aus Texturen beziehen. Dies können sein:
diffuse Materialfarbe (Color-Map)
spiegelnde Materialfarbe (Gloss-Map)
ambiente Materialfarbe
Phong-Exponent
emittierte Intensität (Glow-Map)
Opazität, Alpha-Anteil (Wolken, Nebel, Feuer)
Versatz der interpolierten Oberflächennormale (Bump-Map)
Aufhellung durch Lichteinfall (Light-Map)
Abdunklung durch Schatten (Dark-Map)
Normalenberechnung
Da man sowohl zur Beleuchtungsberechnung als auch für das Normal-Mapping und Cube-Mapping die Normale einer Oberfläche benötigt, wird ihre Berechnung an dieser Stelle erläutert. Die Normale (Vertex-Attribut) ist derjenige Vektor, der senkrecht auf einer Fläche steht.
Zunächst kann man die (Einheits-) Normale für jedes gegen den Uhrzeigersinn (counter clockwise) orientierte Dreieck mit den Eckpunkten , und wie folgt berechnen:
.
Da aber die Vertices i.A. zu mehreren Flächen gehören, berechnet man die Normale für ein Vertex, indem man den Durchschnittswert aller Dreiecks-Normalen bildet, die dieses Vertex benutzen:
, bei k an den Vertex grenzenden Dreiecken
Normalen werden in den View-Space transformiert, indem sie mit der transponierten, inversen Model-View-Matrix (auch World-View-Matrix) multipliziert werden.
Texturkoordinaten
Jedes texturierte Polygon besitzt ein korrespondierendes 2D-Polygon im Texturkoordinatensystem. Die Texturkoordinaten heißen bei DirectX u (in horizontaler Richtung) und v (in vertikaler Richtung) und erstrecken sich von 0.0 bis 1.0, unabhängig von der Größe der Textur. Der Ursprung ((0.0, 0.0)) ist links oben. Für jedes Vertex definiert man die Texturkoordinaten im Texturkoordinatensystem. Diese werden dann für jedes Pixel eines Primitivs interpoliert. Für jedes (u, v)-Paar kann DirectX dann die Farbe des Texels (Pixel im Texture-Space) ermitteln (siehe Filterung von Texturen) und diese Farbe zum Texturieren benutzen.
Abb. 2.4.2 Verwendung der Texturkoordinaten
Bump-Mapping und Normal-Mapping
Die Oberflächendetails einer Oberfläche werden generell durch die Beleuchtung an den Eckpunkten festgelegt. Dies verhindert aber, dass man Details einer Oberfläche erkennt, die kleiner als ein Dreieck sind. Bump-Mapping generiert die Illusion von einer größeren Detailliertheit einer Oberfläche, indem es eine Texture-Map, benutzt um den Normalenvektor über die Pixel eines Primitivs zu variieren. Die Information über die Variation des Normalenvektors ist in einem 2-dimensionalen Array von 3-dimensionalen Vektoren gespeichert, der Bump-Map. Diese kann aus einer Heightmap berechnet werden. Um eine Strukturierung der Oberfläche zu erreichen, wird der Licht- und Betrachtervektor an den Eckpunkten definiert und über die Oberfläche interpoliert. An jedem Pixel wird dann die Normale aus der Bump-Map gelesen und in wenigen Texturstufen eine Pixelschattierung gemäß Phong/Blinn durchgeführt.
Normal-Mapping verwendet statt des Offsets des Normalenvektors absolute Normalenvektoren in der Normal-Map.
DirectX verwendet seit Version 6 das so genannte Environment-Bump-Mapping (EMBM), welches von der Hardware unterstützt werden muss. Hierbei wird ein Offset der Texturkoordinaten in der Bump-Map gespeichert, die dann in der darauf folgenden Texturstufe angewendet werden. Außerdem können die Texturkoordinaten noch durch eine 2×2 Matrix transformiert werden, wodurch eine Bewegung der Struktur erreicht werden kann. EMBM erwartet in der nächsten Stufe eine Environment-Map, auf die der Effekt dann angewandt wird. WaveGen benutzt EMBM in der Klasse Water3D. Normal-Mapping und Bump-Mapping ist in den Effekten Effect1.xml und Effect2.xml implementiert.
Tangenten-Koordinatensystem
Vektoren, die in einer Textur gespeichert sind werden normalerweise relativ zur texturierten Oberfläche interpretiert. So beziehen sich die Normalenvektoren einer Normal-Map auf die Fläche des Primitivs. Sie befinden sich in einem lokalen Koordinatensystem, das durch Vertex-Normale, Tangente und Binormale (senkrecht zu Tangente und Normale) definiert ist, dem Tangenten-Koordinatensystem. Um die Vektoren, die im Tangenten-Koordinatensystem definiert sind, für die Pixelschattierung verwenden zu können, gibt es folgende Möglichkeiten:
die Textur-Vektoren werden vom Tangenten-Koordinatensystem in das View-Koordinatensystem transformiert
die benötigten Vektoren wie Vertex-Normale, Betrachtervektor und Lichtvektor werden aus dem View-Koordinatensystem in das Tangenten-Koordinatensystem transformiert
Der zweite Fall ist bei WaveGen im Effekt Effect1.xml implementiert.
Filterung von Texturen
Die interpolierte Texturkoordinate fällt i. A. nicht auf das Zentrum eines Pixels. Man kann sich die Textur als kontinuierliches Signal vorstellen, dass an der gesuchten Stelle abgetastet wird (Texture-Sampling). Zu diesem kontinuierlichen Signal muss dann ein konkreter Wert rekonstruiert werden. Dies geschieht, indem man einen Filterkern zur Summation der umliegenden Texel verwendet. Das Inverse-Mapping macht einen Rückwärtsabbildung eines quadratischen Pixels in die Textur. Dort wird dann ein allgemeines Viereck erzeugt. Nun kann man die Farbe des Pixels durch eine Mittelung der durch das Viereck überdeckten Texel erreichen. Da Randtexel nur anteilig gewichtet werden, entsteht als Filterkern ein Trapezfilter.
Abb. 2.4.3 Inverse-Mapping
Intuitiv sieht man, dass die Größe des Filterkerns mit der Pixelfläche, also dem Abtastabstand steigt. Wenn man also weit von einem Objekt entfernt ist, sind mehr Texel für ein Pixel verantwortlich, da das Pixel im Verhältnis zur Textur größer wird (Minification). Andersherum sind nur wenige Texel für ein Pixel verantwortlich oder es bekommen sogar mehrere Pixel die Farbe eines Texels, wenn man sich nah an einem Objekt befindet (Magnification). Magnification führt zu grobklotzigen Texturen, Minification zu verschwommenen Texturen.
Der beste Fall besteht immer, wenn die texturierte Fläche etwa so groß wie die Textur ist. Deshalb gibt es die Möglichkeit, eine Textur in mehreren Auflösungen zu verwenden. Es wird dann immer diejenige zur Texturierung ausgewählt, die am Besten zur texturierten Fläche passt. Die niedriger aufgelöste Textur hat dabei exakt die halbe Größe der höher aufgelösten Textur. Dieses Verfahren nennt sich Mip-Mapping (Mip = multum in parvo, lat. für „viel in wenig“). DirectX kann die Mip-Map-Stufen generieren und wählt dann automatisch die passenden Auflösungen aus. Das Problem dabei ist, dass es zwischen zwei Texturstufen eine Filterung geben muss.
Da die Herleitung eines „perfekten“ Filterkerns zu komplex ist, gibt es einige einfachere Filtermethoden. Sie benutzen in Annäherung eines Trapezes einen quadratischen Filterkern.
Point-Sampling: Dies ist der einfachste Filter. Er benutzt die Texturkoordinaten, die als Floating-Point-Wert vorliegen und nimmt die am nächsten liegenden Integer-Werte als endgültige Koordinaten.
Bilinearer Filter: Hierbei werden die vier nächsten Texel entsprechend ihrer Distanz zu den Texturkoordinaten gewichtet und addiert. Kombiniert mit Mip-Mapping wird die Bildqualität im Vergleich zum Point-Sampling erheblich verbessert.
Trilinearer Filter: Der tilineare Filter erfordert zwangsläufig Mip-Mapping. Er benutzt statt eines Mip-Levels die zwei nächsten Mip-Levels. Auf jedem Level wird ein bilinearer Filter angewendet. Die beiden resultierenden Pixel werden entsprechend ihrer Nähe zum idealen Mip-Level kombiniert. Ist der ideale Mip-Level beispielsweise 4.2, so multipliziert man 0.8 mit dem bilinearen Wert der Stufe 4 und addiert das zu 0.2*(bilinearer Wert der Stufe 5).
Anisotroper Filter: Der anisotrope Filter erzielt zu Lasten der Performance bessere Ergebnisse, indem er ein Oval als Filterkern benutzt.
Cube-Mapping
Spiegelnde Objekte wie Wasser bilden ihre Umgebung ab. Wenn die Umgebung im Verhältnis zur Größe des Objektes weit entfernt ist, wie es z.B. bei einer Skybox (Horizont) der Fall ist, hängt die gespiegelte Umgebung vom gespiegelten Vektor zum Betrachter und damit von der Orientierung der Stelle ab, aber nicht von ihrer Position. Dieser Umstand wird genutzt, indem eine Umgebungstextur mit dem gespiegelten Betrachtervektor adressiert wird. Man benutzt hierzu eine Cube-Map. Dies ist ein Schnittmuster eines sechsseitigen Hohlwürfels. Die Texturadressierung berechnet dann aus dem gespiegelten Betrachtervektor die zutreffende Würfelseite mit der darin befindlichen Texturkoordinate.
Abb. 2.4.4 Berechnung der Texturkoordinaten einer Cube-Map
Weil eine Skybox genauso aufgebaut ist wie eine Cube-Map, kann man die Skybox leicht in eine Cube-Map umwandeln und so die Umgebung in einer Textur spiegeln (siehe Kapitel 5.14). Leider funktioniert dies nur mit globalen Reflexionen. Lokale Reflexionen werden zusammen mit projektivem Texture-Mapping in Kapitel 4 behandelt.